Google Taught an AI That Sorts Cat Photos to Analyze DNA

ktsdesign/Shutterstock.com





And it’s very good at it.
When Mark DePristo and Ryan Poplin began their work, Google’s artificial intelligence did not know anything about genetics. In fact, it was a neural network created for image recognition—as in the neural network that identifies cats and dogs in photos uploaded to Google. It had a lot to learn.
But just eight months later, the neural network received top marks at an FDA contest for accurately identifying mutations in DNA sequences. And in just a year, the AI was outperforming a standard human-coded algorithm called GATK. DePristo and Poplin would know; they were on the team that originally created GATK.
It had taken that team of 10 scientists five years to create GATK. It took Google’s AI just one to best it.
“It wasn’t even clear it was possible to do better,” says DePristo. They had thrown every possible idea at GATK. “We built tons of different models. Nothing really moved the needle at all,” he says. Then artificial intelligence came along.
This week, Google is releasing the latest version of the technology as DeepVariant. Outside researchers can use DeepVariant and even tinker with its code, which the company has published as open-source software.
DeepVariant, like GATK before it, solves a technical but important problem called “variant calling.” When modern sequencers analyze DNA, they don’t return one long strand. Rather, they return short snippets maybe 100 letters long that overlap with each other. These snippets are aligned and compared against a reference genome whose sequence is already known. Where the snippets differ with the reference genome, you probably have a real mutation. Where the snippets differ with the reference genome and with each other, you have a problem.
GATK tries to solve the problem with a lot of statistics. DNA-sequencing machines sometimes make mistakes, so the GATK team studied where the machines tend to made mistakes. (The letters GTG are particularly error-prone, to give just one example.) They thought long and hard about things like “the statistical models underlying the Hidden Markov model,” per DePristo. GATK then gives its best guess for the actual letter at a certain location in DNA.
DeepVariant, on the other hand, still does not know anything about DNA-sequencing machines. But it has digested a lot of data. Neural networks are often analogized as layers of “neurons” that deal in progressively more complex concepts—the first layer might respond to light, the second shapes, the third actual objects. As DeepVariant is trained with data, it learns which “neurons” to weigh more heavily and which to ignore. Eventually, it can sort the actual mutations from the errors.
To fit the DNA-sequencing data to an image-recognition AI, the Google team came up with a work-around: Just make it an image! When scientists want to investigate a mutation, they’ll often pull up the aligned snippets, like so:
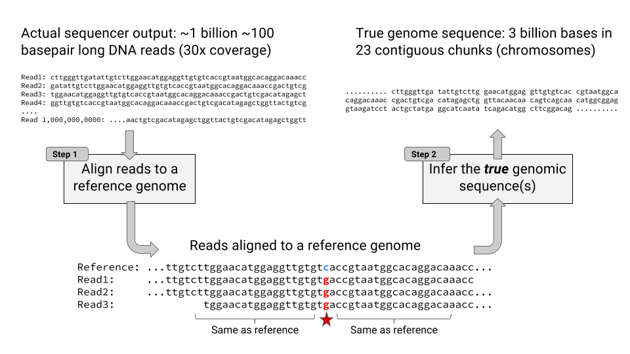
“If humans are doing this as a visual task, why not present this as a visual task?” says Poplin. So they did. The letters—A, T, C, or G—got assigned a red value; the quality of the sequencing at that location a green value; and which strand of DNA’s two strands it is on a blue value. Together, they formed an RGB (red, green, blue) image.
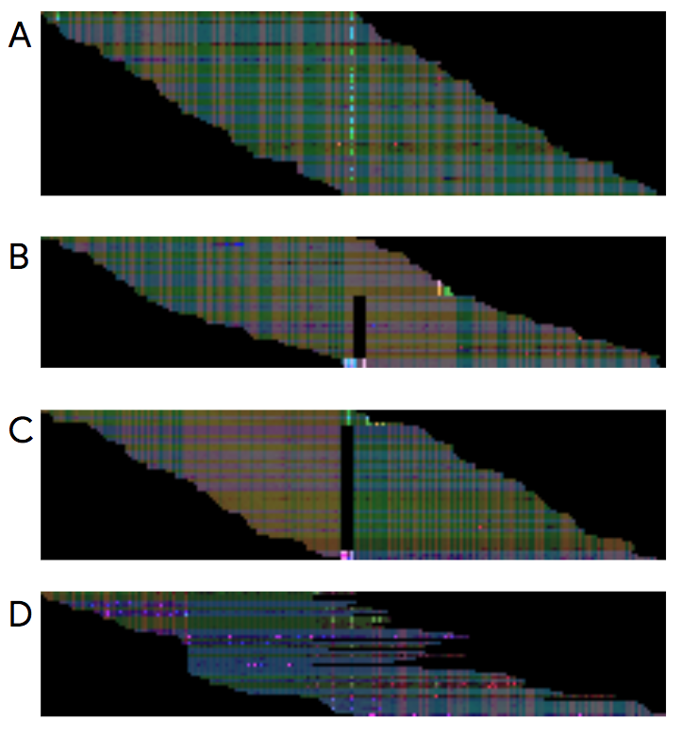
And then it was simply a matter of feeding the neural network data. “It changes the problem enormously from thinking super hard about the data to looking for more data,” says DePristo.
Between publishing a preprint about DeepVariant last December and the release this week, the team continued improving the tool. Instead of three layers of data—represented by red, green, and blue—at any location in the genome, DeepVariant now considers seven. It would no longer make any sense as an image to the human eye. But to a machine, what’s just a few more layers of numbers?
To be clear, DeepVariant itself is unlikely to change genetics research. It is better than GATK, but only slightly so—and it is half as fast depending on the conditions. It does, however, lay the groundwork for AI’s influence in future genetics research.
“The test will really be how it can translate to other technologies,” says Manuel Rivas, a geneticist at Stanford. New sequencing technologies like Oxford Nanopore are becoming popular. If DeepVariant can quickly learn variant calling under these new conditions—remember the humans took five years with GATK—that could speed up the adoption of new sequencing technologies.
DePristo says that the idea of layering data on top of each location in the genome could easily be applied to other problems in genetics—the more important of which is predicting the effects of a mutation. You might imagine layering on, for example, data on when genes are active or not. DeepVariant started off with just three layers of data. Now it has seven. Eventually it might be dozens. It won’t make much sense to a human brain anymore, but to an AI, sure.