Why the Pandemic Experts Failed

Bill Oxford/istockphoto





We're still thinking about the pandemic data in wrong ways.
This story was originally published by The Atlantic. Subscribe to the magazine’s newsletters.
A few minutes before midnight on March 4, 2020, the two of us emailed every U.S. state and the District of Columbia with a simple question: How many people have been tested in your state, total, for the coronavirus?
By then, about 150 people had been diagnosed with COVID-19 in the United States, and 11 had died of the disease. Yet the CDC had stopped publicly reporting the number of Americans tested for the virus. Without that piece of data, the tally of cases was impossible to interpret—were only a handful of people sick? Or had only a handful of people been tested? To our shock, we learned that very few Americans had been tested.
The consequences of this testing shortage, we realized, could be cataclysmic. A few days later, we founded the COVID Tracking Project at The Atlantic with Erin Kissane, an editor, and Jeff Hammerbacher, a data scientist. Every day last spring, the project’s volunteers collected coronavirus data for every U.S. state and territory. We assumed that the government had these data, and we hoped a small amount of reporting might prod it into publishing them.
Not until early May, when the CDC published its own deeply inadequate data dashboard, did we realize the depth of its ignorance. And when the White House reproduced one of our charts, it confirmed our fears: The government was using our data. For months, the American government had no idea how many people were sick with COVID-19, how many were lying in hospitals, or how many had died. And the COVID Tracking Project at The Atlantic, started as a temporary volunteer effort, had become a de facto source of pandemic data for the United States.
After spending a year building one of the only U.S. pandemic-data sources, we have come to see the government’s initial failure here as the fault on which the entire catastrophe pivots. The government has made progress since May; it is finally able to track pandemic data. Yet some underlying failures remain unfixed. The same calamity could happen again.
Data might seem like an overly technical obsession, an oddly nerdy scapegoat on which to hang the deaths of half a million Americans. But data are how our leaders apprehend reality. In a sense, data are the federal government’s reality. As a gap opened between the data that leaders imagined should exist and the data that actually did exist, it swallowed the country’s pandemic planning and response.
The COVID Tracking Project ultimately tallied more than 363 million tests, 28 million cases, and 515,148 deaths nationwide. It ended its daily data collection last week and will close this spring. Over the past year, we have learned much that, we hope, might prevent a project like ours from ever being needed again. We have learned that America’s public-health establishment is obsessed with data but curiously distant from them. We have learned how this establishment can fail to understand, or act on, what data it does have. We have learned how the process of producing pandemic data shapes how the pandemic itself is understood. And we have learned that these problems are not likely to be fixed by a change of administration or by a reinvigorated bureaucracy.
That is because, as with so much else, President Donald Trump’s incompetence slowed the pandemic response, but did not define it. We have learned that the country’s systems largely worked as designed. Only by adopting different ways of thinking about data can we prevent another disaster:
1. All Data are Created; Data Never Simply Exist
Before March 2020, the country had no shortage of pandemic-preparation plans. Many stressed the importance of data-driven decision making. Yet these plans largely assumed that detailed and reliable data would simply … exist. They were less concerned with how those data would actually be made.
So last March, when the government stopped releasing testing numbers, Nancy Messonnier, the CDC’s respiratory-disease chief, inadvertently hinted that the agency was not prepared to collect and standardize state-level information. “With more and more testing done at states,” she said, the agency’s numbers would no longer “be representative of the testing being done nationally.”
When we started compiling state-level data, we quickly discovered that testing was a mess. First, states could barely test anyone, because of issues with the CDC’s initial COVID-19 test kit and too-stringent rules about who could be tested. But even beyond those failures, confusion reigned. Data systems have to be aligned very precisely to produce detailed statistics. Yet in the U.S., many states create one sort of data for themselves and another, simpler feed to send to the federal government. Both numbers might be “correct” in some sense, but the lack of agreement within a state’s own numbers made interpreting national data extremely difficult.
The early work of the COVID Tracking Project was to understand those inconsistencies and adjust for them, so that every state’s data could be gathered in one place. Consider the serpentine journey that every piece of COVID-19 data takes. A COVID-19 test, for instance, starts as a molecular reaction in a vial or lab machine, then proceeds through several layers of human observation, keyboard entry, and private computer systems before reaching the government. The pipelines that lead to county, state, and federal databases can be arranged in many different ways. At the end of the process, you have a data set that looks standardized, but may actually not be.
Yet the federal pandemic response was built on the assumption that those data were fundamentally sound, and that they could be fed into highly tuned epidemiological models that could guide the response. Inside the government, the lack of data led to a sputtering response. “What CDC is not accounting for is that we have been flying blind for weeks with essentially no [testing],” Carter Mecher, a medical adviser at the Department of Veterans Affairs, wrote to an email list of federal officials on March 13. “The difference between models and real life is that with models we can set the parameters as if they are known. In real life, these parameters are as clear as mud.”
We now know that early case counts reflected only a small portion of the true number of cases. They were probably 10 or even 20 times too small, according to later academic studies. The government missed the initial explosion of COVID-19 cases because, despite its many plans to analyze data, it assumed that data would simply materialize.
2. Data are a Photograph, Not a Window
By late spring of last year, the COVID Tracking Project’s Peter Walker had developed a simple way to visualize the sweep of the pandemic—four bar charts, presented in a row, showing tests, cases, hospitalized patients, and deaths. This chart has since aired on dozens of local news stations, and has been used by state and federal officials to view COVID-19’s path over time.
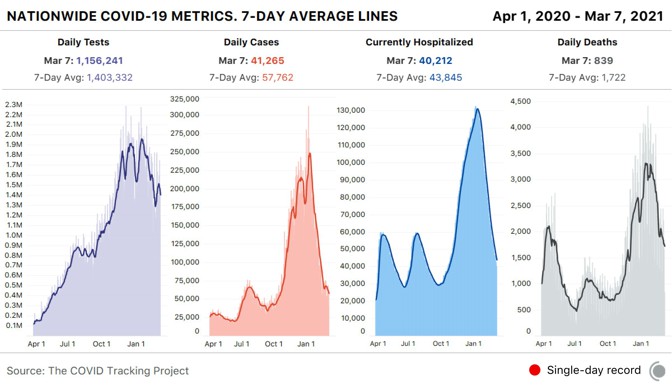
The charts seem authoritative, comprehensive. Yet the work of producing these data has taught us that every metric represents a different moment in time. You aren’t really looking at the present when you look at these charts—you’re looking at four different snapshots of the past.
The COVID Tracking Project’s research, led by Kara Schechtman and Michal Mart, has found that the data travel “at different speeds.” Take case and test data—the two factors that go into the “test-positivity rates,” which officials have used to trigger lockdowns, reopenings, and other pandemic policy measures. Case numbers can move quickly; negative test results flow more slowly. Combine them, and the dates of tests and cases may not match up. Individual states can make adjustments for this kind of problem, but comparisons across states remain difficult. Worse, while negative test results lag, test-positivity rates will look higher than they actually are, keeping schools and businesses from reopening.
The death data are also shaped by reporting systems in ways that few people—even top officials—seemed to understand. Although the CDC estimates that the median death is reported to state authorities about 20 days after the person has actually died, a huge range exists. About a quarter of deaths are reported less than six days after they have occured; another 25 percent are reported more than 45 days after. And the lags are simply not constant, as the epidemiologist Jason Salemi has shown with Florida data. These reporting quirks make it very difficult to assess the death toll for an outbreak until many weeks after the surge has ebbed.
There are other invisible problems in the data. For one, we have no idea how many antigen tests have been conducted in the United States. A recent government document estimated that 4 million of these rapid tests are now being conducted a day—more than twice the number of slower, but more accurate, polymerase-chain-reaction, or PCR, tests. Yet states report nowhere near that volume of antigen tests. Tens of millions of tests are going unreported. Where are they happening? How many are coming out positive? No one has any idea.
The data set that we trust the most—and that we believe does not come with major questions—is the hospitalization data overseen by the Department of Health and Human Services. At this point, virtually every hospital in America is reporting to the department as required. We now have a good sense of how many patients are hospitalized with COVID-19 around the country.
This has allowed the federal government to target aid, deploying health-care personnel, medicine, and personal protective equipment to the hospitals that need it most—a clear example of how accurate pandemic data can help policy makers.
3. Data are Just Another Type of Information
Data seem to have a preeminent claim on truth. Policy makers boast about data-driven decision making, and vow to “follow the science.” But we’ve spent a year elbow-deep in data. Trust us: Data are really nothing special.
Data are just a bunch of qualitative conclusions arranged in a countable way. Data-driven thinking isn’t necessarily more accurate than other forms of reasoning, and if you do not understand how data are made, their seams and scars, they might even be more likely to mislead you.
This problem has hampered the pandemic response from the start. By early March, it was evident that the virus should have been spreading in the U.S. Yet the CDC’s stringency about who could be tested and the lack of clear testing data meant many federal leaders simply didn’t acknowledge that reality.
Today, these issues somehow remain. In a press conference on March 1, 2021, the new CDC director, Rochelle Walensky, cautioned the public about new coronavirus variants. Cases and deaths were both rising nationwide, she warned, potentially implying that the mutated versions of the virus were to blame. But at the COVID Tracking Project, we knew this narrative of a variant-driven surge didn’t hold. If deaths were rising now, that meant cases had risen a month ago. This didn’t add up—a month earlier, cases had been falling, precipitously.
Instead, we knew from following the data closely that many states were reporting huge backlogs as they examined death certificates. At the same time, Texas and several other states had been crushed by a winter storm. This sent their reporting plummeting—deaths dipped faster than they should have, and then shot back up, when work fully resumed. Since Walensky spoke, the average number of deaths a day has fallen by almost 25 percent.
In other words, it wasn’t that the pandemic in those states had gotten worse in February, but that the peak straddling December and January had been even more damaging than we knew at the time. Public-health officials continue to believe that the data in front of them can be interpreted without sufficient consideration of the data-production process.
And so deep problems with the data persist. The COVID Tracking Project has shown that at least five states have disturbingly incomplete testing data. In some states, 80 percent of tests are missing from the equivalent federal data set. Yet the CDC is referring leaders of those states to its own test-positivity-rate data—which are calculated from these inaccurate data—when they consider reopening their schools.
Because of the painstaking labor of its more than 550 contributors, the COVID Tracking Project was among the first to identify virus surges in the Sun Belt and the Midwest; it determined the outsize importance of nursing homes in driving COVID-19 deaths; and it found widespread evidence of overwhelmed hospitals during the harsh winter surge. Our data have been used by The New York Times, Johns Hopkins University, and two presidential administrations.
Data are alluring. Looking at a chart or a spreadsheet, you might feel omniscient, like a sorcerer peering into a crystal ball. But the truth is that you’re much closer to a sanitation worker watching city sewers empty into a wastewater-treatment plant. Sure, you might learn over time which sewers are particularly smelly and which ones reach the plant before the others—but you shouldn’t delude yourself about what’s in the water.
The scientists at the CDC clearly have far more expertise in infectious-disease containment than almost anyone at the COVID Tracking Project or The Atlantic. But we did spend a year grappling with the limitations of the system that Walensky and President Joe Biden now depend on. Perhaps no official or expert wants to believe that the United States could struggle at something as seemingly basic as collecting statistics about a national emergency. Yet at the COVID Tracking Project, we never had the luxury of that illusion. We started with a simple mission—to count tests nationwide—and, in pursuing it, immediately found ourselves enmeshed in the problems of defining and standardizing tests, cases, hospitalizations, and deaths. In the cracks of federalism, where the state and national governments grate against each other, we found alarming levels of chaos, but lurking within the chaos was the truth. We saw, in that dark place, how our public-health systems actually worked, not how we wished they would.
To avoid another data calamity, our public-health system must expend as much energy on understanding the present as it does on modeling the future. Governing through a pandemic—or any emergency—is about making the least-bad decisions with the best information available. That information can take many forms; it doesn’t have to be data. But if you do look at the data, then you must understand how each point, each cell, was made; otherwise, you’re likely to be misled.
Our leaders should also put some faith in the capabilities of those whom they govern. The COVID Tracking Project clung to one principle: We told people the truth as we could discern it. We didn’t say what we wanted to be true, nor what we hoped would engender a specific public response.
Working on the COVID Tracking Project has been the honor of our lives. For a year, every day, dozens of volunteers—programmers, librarians, high schoolers, a former hotel manager—came together to make an honest account of one of the most horrifying ordeals that any of us had ever experienced. This team of former strangers, united by concern and curiosity, salvaged something useful from the din. We held fast to one another, and we made sense of the world as we could.